| Cohesity Marketplace |
| AWS Marketplace |
| Azure Marketplace |
Automate the discovery and masking of sensitive data, generating synthetically identical customer data that:
✔ Looks and behaves just like real data (so your applications, AI models and tests function as expected).
✔ Maintains relationships and consistency across tables, files, databases and environments.
✔ Cannot be reverse-engineered back to real customer data - ensuring compliance with GDPR, CCPA, HIPAA and more.

Regulations and standards like CCPA, GDPR, the Privacy Act, ISO 27001 and HIPAA require a secure approach to handling customer data - but security and compliance no longer has to come at the cost of innovation. DataMasque's synthetically identical customer data allows your teams to develop and test software, analyze data and power AI/ML models with confidence - unlocking insights and innovation without risk or regulatory roadblocks.
As data leaves your production environment, DataMasque simply and irreversibly replaces the customer data with synthetically identical customer data that is realistic, functional and consistent.




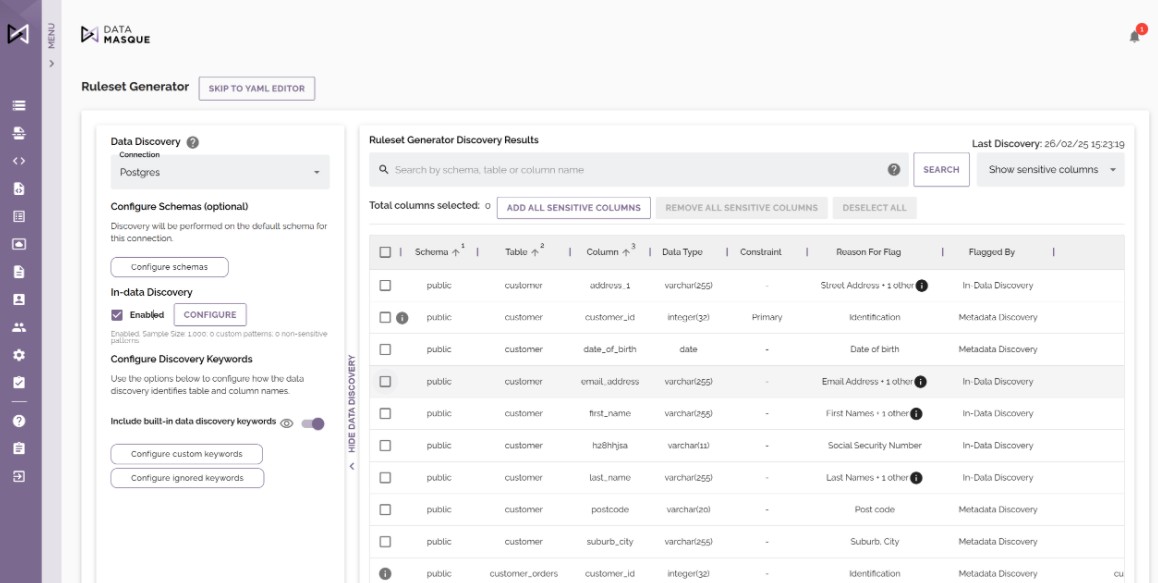
DataMasque provides powerful discovery functionality, to identify and classify sensitive customer data including metadata keyword search and in-data patterns from both our built-in keywords and patterns, as well as custom patterns set by the user.
DataMasque has been designed with modern enterprise environments in mind. With horizontal scalability, containerised deployment model, and automation API, DataMasque can seamlessly slot into your existing data provisioning process or DevOps pipeline – regardless of whether you’re running on-prem or in a public cloud environment.
DataMasque provides consistency of data across different environments, including tables, files, databases, clouds, and even organizations. DataMasque supports masking of primary keys and unique keys, and automatically maintains referential integrity of foreign keys. This ensures data consistency across all occurrences of information ‘types’, which are masked using the same algorithm across files, tables, databases, and database engines.
DataMasque generates synthetically identical customer data that is realistic and representative of production datasets meaning data quality and security are no longer a compromise. DataMasque ‘imitates’ datasets by ensuring that the value of the data is retained without any personally identifiable information, giving you the same data functionality and statistical benefit.
If the data is dynamically masked or encrypted, it means your sensitive data can be unlocked to its original state. With DataMasque, we remove your PII and replace it with synthetically identical customer data that looks just like the original but poses no risk of re-identification.
The only constant is change which is why DataMasque developed a proactive sensitive data alert. This alerts you when there has been a schema change that has been flagged as containing potentially sensitive data. Our sensitive data discovery doesn’t just look for what we think is sensitive, you can upload your own data dictionary for our tool monitor.
| Name | ID Number | Card Number |
|---|---|---|
John/ Smith | 221-22-1111 | 5565-5700-2427-7079 |
Kimberly. Berry | K00-09-7443 | - |
Walter Allan | AA876078TT | 3415-4157-7075-207 |
| Name | ID Number | Card Number |
|---|---|---|
Brian/ Main | 004-99-2756 | 8573232224112097 |
Jane/ Doe | 400-23-8620 | 2116593810151072 |
Tom/ Hanks | 765-76-8736 | 9771222776019352 |
| Name | ID Number | Card Number |
|---|---|---|
Brian/ Main | 004-99-2756 | 5565-0294-1312-1209 |
Jane. Doe | T39-32-2876 | - |
Tom Hanks | VD576873RE | 3415-1200-6511-123 |
| Cohesity Marketplace |
| AWS Marketplace |
| Azure Marketplace |
| Platform | Version |
|---|---|
| Ubuntu | 20.04, 22.04, or 24.04 LTS (x86 64-bit) |
| Red Hat Enterprise Linux | RHEL 8.7+, 9.x (x86 64-bit) |
| Oracle Linux | 9.x (x86 64bit) |
| Amazon EKS | Kubernetes 1.29-1.33 |
| Amazon Linux | 2023 (x86 64-bit) |
| Red Hat Openshift on AWS (ROSA) | 4.17 |
| Database | Version |
|---|---|
| Oracle Database | 11gR2, 12gR1, 12gR2, 18c, 19c |
| Microsoft SQL Server | 2012, 2014, 2016, 2017, 2019, 2022 |
| MariaDB | 10.11, 11.2 |
| MySQL | 5.7, 8 |
| PostgreSQL | 9.6, 10, 11, 12, 13, 14, 15, 16 |
| IBM Db2 LUW | 11.5 |
| Amazon Aurora | - |
| Amazon RDS | - |
| Amazon Redshift | - |
| Amazon DynamoDB | - |
| Azure SQL Server | - |
| Snowflake | - |
| Unstructured data in text files or database columns |
| Storage Platforms | AWS S3, Azure Blob Storage, NFS and SMB |
| Tabular | CSV (and other character delimited), Fixed Width & Parquet files |
| Object | JSON & XML files |
| Multi-Record | Apache Avro & NDJSON files |
Choose your plan | Free Trial (30 days) | Cloud Consumption | Business | Enterprise |
|---|---|---|---|---|
| Get in touch | Get in touch | Get in touch | Get in touch | |
| Mask Data Size | Up to 1000 rows per run | Up to 500 GB | Unlimited | Unlimited |
Data sources:
| One (1) data source included of any type | One (1) data source included of any type | All data sources included | |
| RESTful API | ||||
| Sensitive Data Discovery | ||||
| Compliance Reporting | ||||
| Automatic masking ruleset generation | ||||
| Parallelism and Multi-processing | ||||
| Proactive Data Discovery | ||||
| Cross Data Store Consistency | ||||
| SSO/SAML | ||||
| Role Based Access Control | ||||
| Safe Data Exchange | ||||
| Masking Templates | ||||
| Product Training | 2hrs | 2hrs | ||
| Support Level | Email only | Standard | Premium |
DataMasque is a data masking tool that enables you to replace sensitive values in databases with artificial but realistic alternatives while maintaining data integrity. Data masking can enhance testing, development and training by providing realistic and functional data in these scenarios without compromising security, privacy or operational accuracy.
DataMasque currently supports most database and file formats. If we don’t have your database listed in our Support Matrix, please reach out to the team as we have connectors and workarounds for even the most obscure databases.
DataMasque is a data masking tool that enables you to replace sensitive values in databases with artificial but realistic alternatives while maintaining data integrity. Data masking can enhance testing, development and training by providing realistic and functional data in these scenarios without compromising security, privacy or operational accuracy. DataMasque supports the following deployment options:
DataMasque can be accessed using a browser-based web interface, which provides a centralized single-pane-of-glass view of your entire data masking environment. DataMasque also provides a robust set of REST API endpoints, allowing you to easily utilize its various features through automated processes.
DataMasque can discover sensitive data by performing a metadata keyword search to provide you with a starting point for data masking, allowing you to prioritize which data sources to protect. Sensitive data discovery tasks can also be included with every data masking run to identify new sensitive information, providing proactive and ongoing protection.
DataMasque removes sensitive data from your database and replaces it with realistic masked data. By default, masked values are randomly generated, preventing recovery of the original data. When data consistency across tables is required, DataMasque generates masked values using cryptographically secure SHA-512 salted hashes of the original values.
DataMasque provides masking algorithms that generate values based on one or more unmasked column values using a cryptographically secure SHA-512 salted hash. Use of these algorithms ensures deterministic masking across columns, tables, and database engines.
DataMasque supports masking of primary keys and unique keys. DataMasque automatically maintains referential integrity of foreign keys and also allows users to propagate masked values to implied foreign keys.
DataMasque currently provides a REST API for triggering and monitoring masking runs using pre-configured connections and rulesets. We have plans to open more API endpoints in the future.
Yes, DataMasque supports a variety of mainframe VSAM / QSAM file types and supports single-pass masking of data defined by copybooks including redefined database in any encoding type. DataMasque also supports complex mainframe interface files that are semi-binary (ie, ASCII as well as compressed binary).
Yes - we have templates for a number of standard EDI files and we are expanding them continually. These are also masked in a single pass of the file and will automatically detect the record delimiters The EDI support expands our support into being able to mask files with any column and record delimiter type.
Yes, DataMasque includes data subsetting capabilities, allowing you to retain a specified percentage of production data for development and test environments. This reduces data volume, enabling cheaper and faster early-stage testing.
Unlike other subsetting tools, DataMasque's subsetting is deterministic, using the same safe random generation as other DataMasque tasks, so the same run secret always produces the same records.